A ideia desse post é mostrar a evolução do prêmio da NTN-B 2045 sobre a taxa de juros neutra da economia, calculada com base em dados extraídos do relatório focus (veja esse post).
Replico aqui parte do código do post anterior apenas para deixar registrado o ponto de largada:
library(rbcb)
library(tidyverse)
inflation <- get_annual_market_expectations(indic = "IPCA")
selic <- get_top5s_annual_market_expectations(indic = "Selic")
inflation_filtered <- inflation |>
mutate(reference_date = as.numeric(reference_date),
n_ahead = reference_date - lubridate::year(date)) |>
filter(n_ahead == 3) |>
select(date, ipca_median = median)
selic_filtered <- selic |>
mutate(reference_date = as.numeric(reference_date),
n_ahead = reference_date - lubridate::year(date)) |>
filter(n_ahead == 3) |>
select(date, selic_median = median)
real_rate_expectations <- left_join(selic_filtered, inflation_filtered, by = "date") |>
mutate(real_rate_median = selic_median - ipca_median) |>
group_by(date) |>
summarise(median = median(real_rate_median)) |>
ungroup()
real_rate_expectations
## # A tibble: 5,115 x 2
## date median
## <date> <dbl>
## 1 2001-11-06 NA
## 2 2001-11-07 NA
## 3 2001-11-08 NA
## 4 2001-11-09 7.5
## 5 2001-11-12 7.5
## 6 2001-11-13 7.5
## 7 2001-11-14 7.5
## 8 2001-11-16 7.5
## 9 2001-11-19 7.5
## 10 2001-11-20 7.5
## # ... with 5,105 more rows
Os dados da NTN-B em excel podem ser encontrados aqui.
# import data
b45 <- readxl::read_excel(
path = "/Meu Drive/site/data/b45.xlsx",
col_types = c("date", "numeric"),
skip = 1)
names(b45)[[1]] <- "date"
names(b45)[[2]] <- "B45"
b45 <- b45 |>
mutate(date = lubridate::as_date(date)) |>
na.omit()
b45
## # A tibble: 4,398 x 2
## date B45
## <date> <dbl>
## 1 2004-09-16 9.1
## 2 2004-09-17 9.10
## 3 2004-09-20 9.10
## 4 2004-09-21 9.10
## 5 2004-09-22 9.10
## 6 2004-09-23 9.10
## 7 2004-09-24 9.1
## 8 2004-09-27 9.1
## 9 2004-09-28 9.1
## 10 2004-09-29 9.1
## # ... with 4,388 more rows
Quando for importar os dados na sua máquina lembre de alterar o caminho de busca. No meu PC é
/Meu Drive/site/data/b45.xlsx, mas no seu poderá ser diferente, dependendo em que pasta você salvar os dados.
É fácil combinar os dois datasets pela data com a função left_joint() do pacote dplyr:
data_for_plot <- real_rate_expectations |>
left_join(b45, by = "date") |>
mutate(premium = B45 - median) |>
filter(date >= "2005-01-02")
data_for_plot
## # A tibble: 4,326 x 4
## date median B45 premium
## <date> <dbl> <dbl> <dbl>
## 1 2005-01-03 8.5 9.10 0.598
## 2 2005-01-04 8.5 9.10 0.599
## 3 2005-01-05 8.5 9.10 0.598
## 4 2005-01-06 8.5 9.09 0.586
## 5 2005-01-07 8.5 9.08 0.581
## 6 2005-01-10 8.5 9.08 0.582
## 7 2005-01-11 8.5 9.07 0.566
## 8 2005-01-12 8.5 9.07 0.570
## 9 2005-01-13 8.5 9.07 0.572
## 10 2005-01-14 8.5 9.08 0.575
## # ... with 4,316 more rows
Nesse caso, o prêmio é calculado como a diferença entre o Yield to Maturity (YTM) das NTN-B’s sobre a taxa neutra da economia.
data_for_plot |>
ggplot(aes(x = date, y = premium / 100, color = premium)) +
geom_line(show.legend = FALSE) +
geom_hline(yintercept = 0.00, size = 2, alpha = 0.5, color = "grey") +
geom_hline(yintercept = 0.02, size = 2, alpha = 0.5, color = "grey") +
scale_y_continuous(labels = scales::percent_format()) +
scale_color_viridis_c() +
labs(
title = "NTN-B 2045 vs. Taxa Neutra",
subtitle = "Prêmio sobre a taxa de equilíbrio (2005-2022)",
x = NULL,
y = "Prêmio"
)
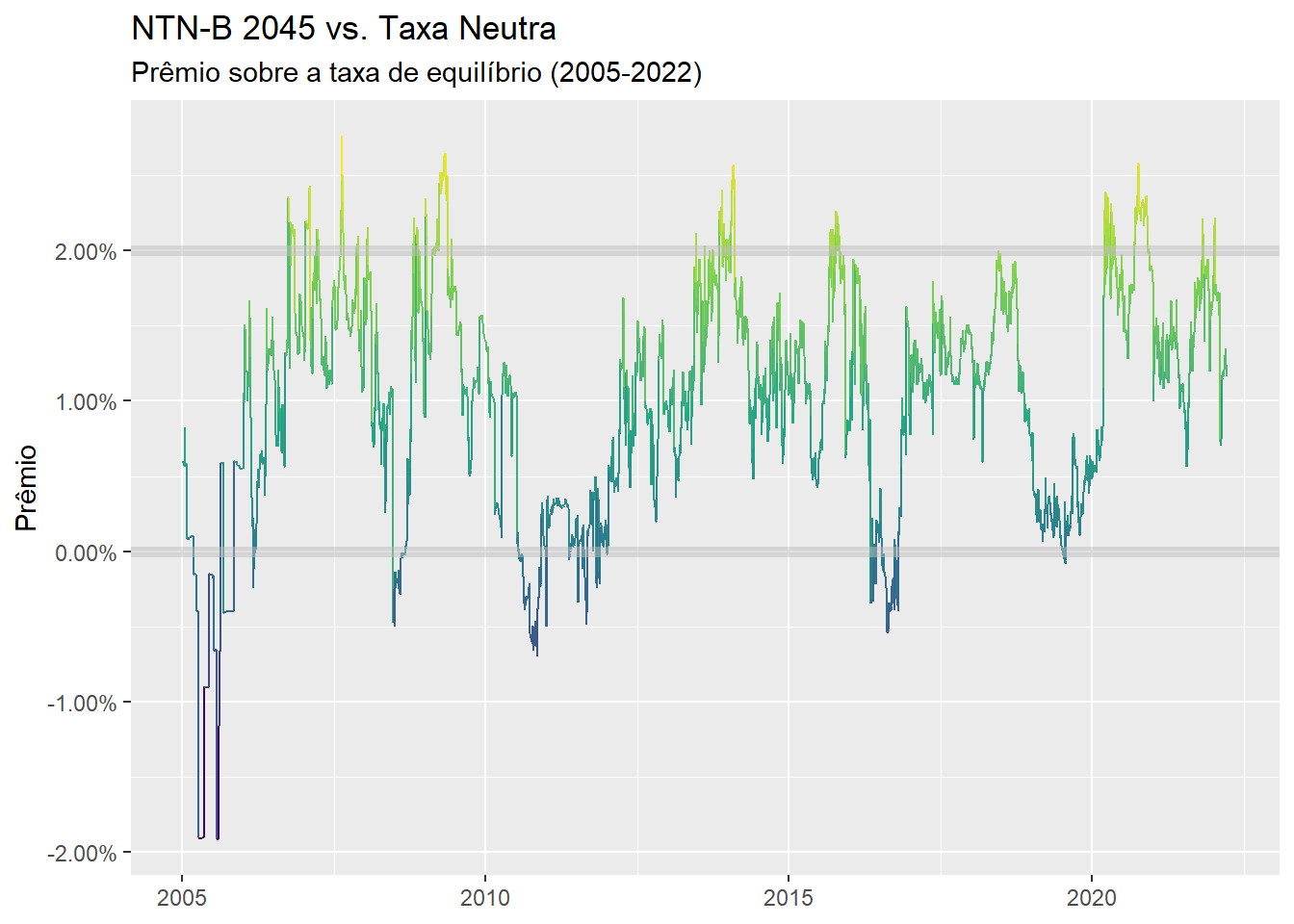
Na maior parte do tempo o prêmio se situa entre \(0\%\) a \(2\%\).
Quanto maior o prêmio, maior a expectativa de retornos futuros (tudo ou mais constante). Nesse sentido, o último grande momento de compra foi em novembro de 2021.
Quem pegou, pegou!