A versão 0.2.0 do ffp finalmente está no CRAN.
Já fazia algum tempo que gostaria de ter lançado essa atualização, que possui algumas melhorias importantes em relação a versão anterior:
- A função
bind_probs()agora adiciona a call do usuário como identificador em uma tidy-tibble:
library(ffp)
library(ggplot2)
x <- exp_decay(EuStockMarkets, lambda = 0.001)
y <- exp_decay(EuStockMarkets, lambda = 0.002)
bind_probs(x, y)## # A tibble: 3,720 x 3
## rowid probs fn
## <int> <ffp> <fct>
## 1 1 0.0001844669 exp_decay(x = EuStockMarkets, lambda = 0.001)
## 2 2 0.0001846515 exp_decay(x = EuStockMarkets, lambda = 0.001)
## 3 3 0.0001848363 exp_decay(x = EuStockMarkets, lambda = 0.001)
## 4 4 0.0001850212 exp_decay(x = EuStockMarkets, lambda = 0.001)
## 5 5 0.0001852063 exp_decay(x = EuStockMarkets, lambda = 0.001)
## 6 6 0.0001853916 exp_decay(x = EuStockMarkets, lambda = 0.001)
## 7 7 0.0001855771 exp_decay(x = EuStockMarkets, lambda = 0.001)
## 8 8 0.0001857627 exp_decay(x = EuStockMarkets, lambda = 0.001)
## 9 9 0.0001859486 exp_decay(x = EuStockMarkets, lambda = 0.001)
## 10 10 0.0001861346 exp_decay(x = EuStockMarkets, lambda = 0.001)
## # ... with 3,710 more rowsComo os dados estão no formato “longo” - tidy - é fácil usar o ggplot2:
bind_probs(x, y) |>
ggplot(aes(x = rowid, y = probs, color = fn)) +
geom_line() +
theme(legend.position = "bottom")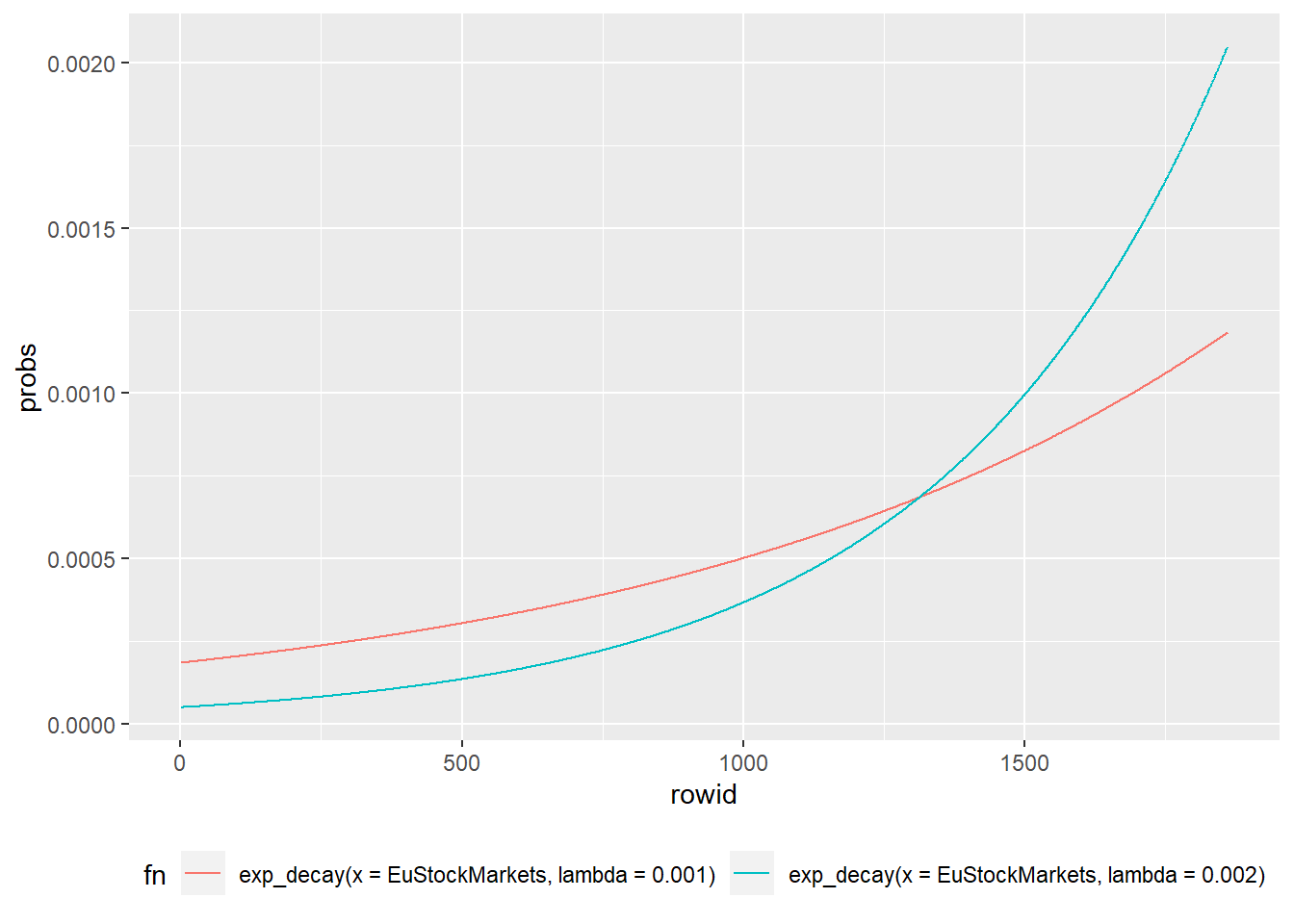
A função
entropy_pooling(), o carro chefe por trás das “probabilidades totalmente flexíveis”, agora é uma função exportável. O objetivo com essa mudança é facilitar a criação de opiniões por parte do usuário, de modo a não limitar sua utilização apenas as alternativas propostas pelo pacote. A função agora também suporta três solvers:nlminb,solnlenloptr(anteriormente todas as otimizações aconteciam utilizandosolnl.)A principal feature desse lançamento é a criação da classe
ffp_views. Essa classe torna mais fácil para o usuário sistematizar a geração de opiniões em praticamente qualquer característica de uma distribuição multivariada (retornos, volatilidades, correlações, copulas, etc.). Veja a família de funçõesview_*();Uma vez que o novo vetor de probabilidades tenha sido calculado, o próximo passo é computar os momentos compatíveis com esse novo vetor. Essa missão pode ser facilmente atingida com a função
ffp_moments(). Os momentos preditivos disponibilizados por essa função podem ser utilizados em um otimizador para construção de uma fronteira eficiente condicional as opiniões do usuário.
Mais sobre essa técnica extraordinária chamada entropy-pooling nos próximos posts.