Quando comecei a usar o R, não demorou muito para que me desse conta que estava sempre repetindo as mesmas tarefas. Assim, decidi sistematizar o acesso ao API do YahooFinance, o que resultou na construção do YahooTickers.
O API do Yahoo não é perfeito, mas funciona bem e é razoavelmente simples. Se você programa com frequência e não tem acesso a Bloomberg, Economatica ou Refinitiv é possível que esse pacote interesse a você.
Para baixar oYahooTickers no RStudio você deve utilizar o seguinte comando no console:
# install.packages("devtools")
# devtools::install_github("Reckziegel/YahooTickers")
Suas principais funcionalidades serão demonstradas utilizando algumas ações do índice Dow Jones como referência:
# bibliotecas necessárias
library(YahooTickers)
library(forecast)
library(ggplot2)
ticks <- get_tickers(dow)
ticks <- ticks |>
dplyr::filter(tickers != "DOW") # essa ação possui histórico relativamente curto
# Chama-se DOW Inc., não confundir com
# o índice Dow Jones.
ticks
## # A tibble: 29 x 1
## tickers
## <chr>
## 1 MMM
## 2 AXP
## 3 AMGN
## 4 AAPL
## 5 BA
## 6 CAT
## 7 CVX
## 8 CSCO
## 9 KO
## 10 GS
## # ... with 19 more rows
O pacote (atualmente) aceita tickers de 23 índices mundiais (aqui você consegue a lista com todas opções disponíveis).
Com os tickers em mãos é possível se conectar ao Yahoo com a função get_stocks():
stocks <- ticks |>
dplyr::slice(1:12) |> # selecionando as 12 primeiras ações
# para tornar a análise mais rápida
get_stocks(periodicity = "monthly")
stocks
## # A tibble: 1,776 x 8
## date tickers open high low close volume adjusted
## <date> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2010-01-01 MMM 83.1 85.2 79.1 80.5 75208100 57.5
## 2 2010-02-01 MMM 80.8 81.8 77.2 80.2 75020400 57.3
## 3 2010-03-01 MMM 80.6 84.5 80.3 83.6 91066100 60.1
## 4 2010-04-01 MMM 83.9 90.2 82.7 88.7 96407000 63.8
## 5 2010-05-01 MMM 89.2 90.5 69.0 79.3 109573600 57.0
## 6 2010-06-01 MMM 78.7 83 72.7 79.0 114407500 57.2
## 7 2010-07-01 MMM 79.1 87.5 77.0 85.5 89556700 61.9
## 8 2010-08-01 MMM 86.8 88.4 78.4 78.6 74721100 56.8
## 9 2010-09-01 MMM 79.5 88 79.3 86.7 64059700 63.1
## 10 2010-10-01 MMM 87.4 91.5 83.8 84.2 82038100 61.3
## # ... with 1,766 more rows
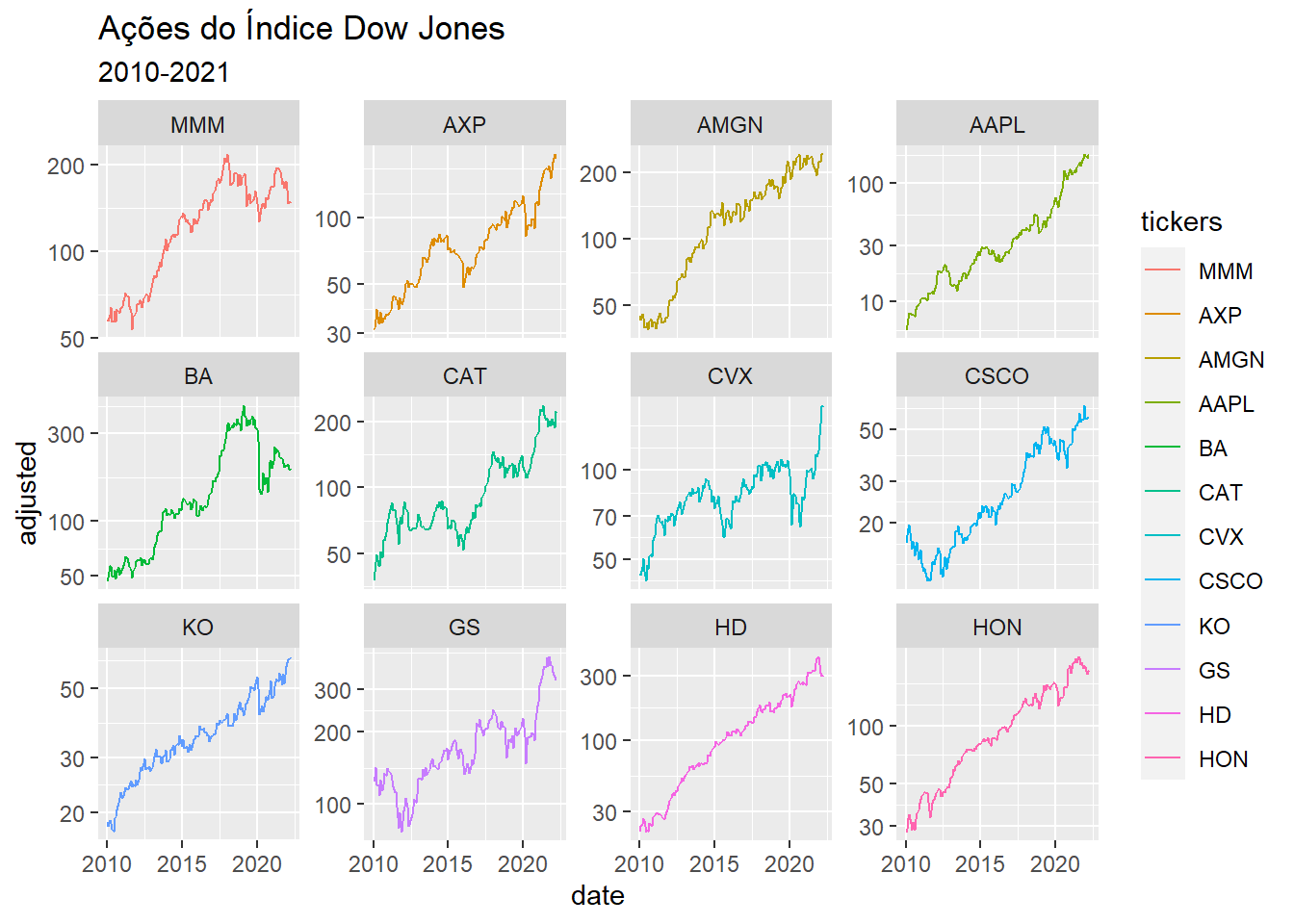
Os dados já vem no formato tidy (longo), de modo a potencializar a iteratividade com o ggplot2 e o todo o ecossistema do tidyverse. Veja:
stocks |>
ggplot(aes(x = date, y = adjusted, color = tickers)) +
geom_line() +
facet_wrap(~tickers, scales = "free_y") +
scale_y_log10() +
labs(title = "Ações do Índice Dow Jones",
subtitle = "2010-2021")
Caso haja interesse em levar a adiante a modelagem econométrica, o usuário tem a opção de utilizar get_returns() e get_models() em sequência:
models <- stocks |>
get_returns(.group = tickers,
.type = arithmetic,
.omit_na = TRUE,
adjusted) |>
get_models(.group = tickers,
.col = adjusted,
.initial = 60,
.assess = 1,
.cumulative = FALSE,
.fun = Arima, # Função Arima do pacote `forecast`
c(1, 0, 0)) # modelo auto-regressivo
models
## # A tibble: 2,088 x 17
## date tickers data term estimate model.desc sigma logLik AIC
## <date> <fct> <list> <fct> <dbl> <fct> <dbl> <dbl> <dbl>
## 1 2015-02-01 MMM <tibble> ar1 -0.217 ARIMA(1,0~ 0.0489 97.0 -188.
## 2 2015-02-01 MMM <tibble> intercept 0.0152 ARIMA(1,0~ 0.0489 97.0 -188.
## 3 2015-03-01 MMM <tibble> ar1 -0.218 ARIMA(1,0~ 0.0489 96.9 -188.
## 4 2015-03-01 MMM <tibble> intercept 0.0156 ARIMA(1,0~ 0.0489 96.9 -188.
## 5 2015-04-01 MMM <tibble> ar1 -0.236 ARIMA(1,0~ 0.0487 97.2 -188.
## 6 2015-04-01 MMM <tibble> intercept 0.0147 ARIMA(1,0~ 0.0487 97.2 -188.
## 7 2015-05-01 MMM <tibble> ar1 -0.202 ARIMA(1,0~ 0.0495 96.2 -186.
## 8 2015-05-01 MMM <tibble> intercept 0.0133 ARIMA(1,0~ 0.0495 96.2 -186.
## 9 2015-06-01 MMM <tibble> ar1 -0.209 ARIMA(1,0~ 0.0469 99.5 -193.
## 10 2015-06-01 MMM <tibble> intercept 0.0149 ARIMA(1,0~ 0.0469 99.5 -193.
## # ... with 2,078 more rows, and 8 more variables: BIC <dbl>, ME <dbl>,
## # RMSE <dbl>, MAE <dbl>, MPE <dbl>, MAPE <dbl>, MASE <dbl>, ACF1 <dbl>
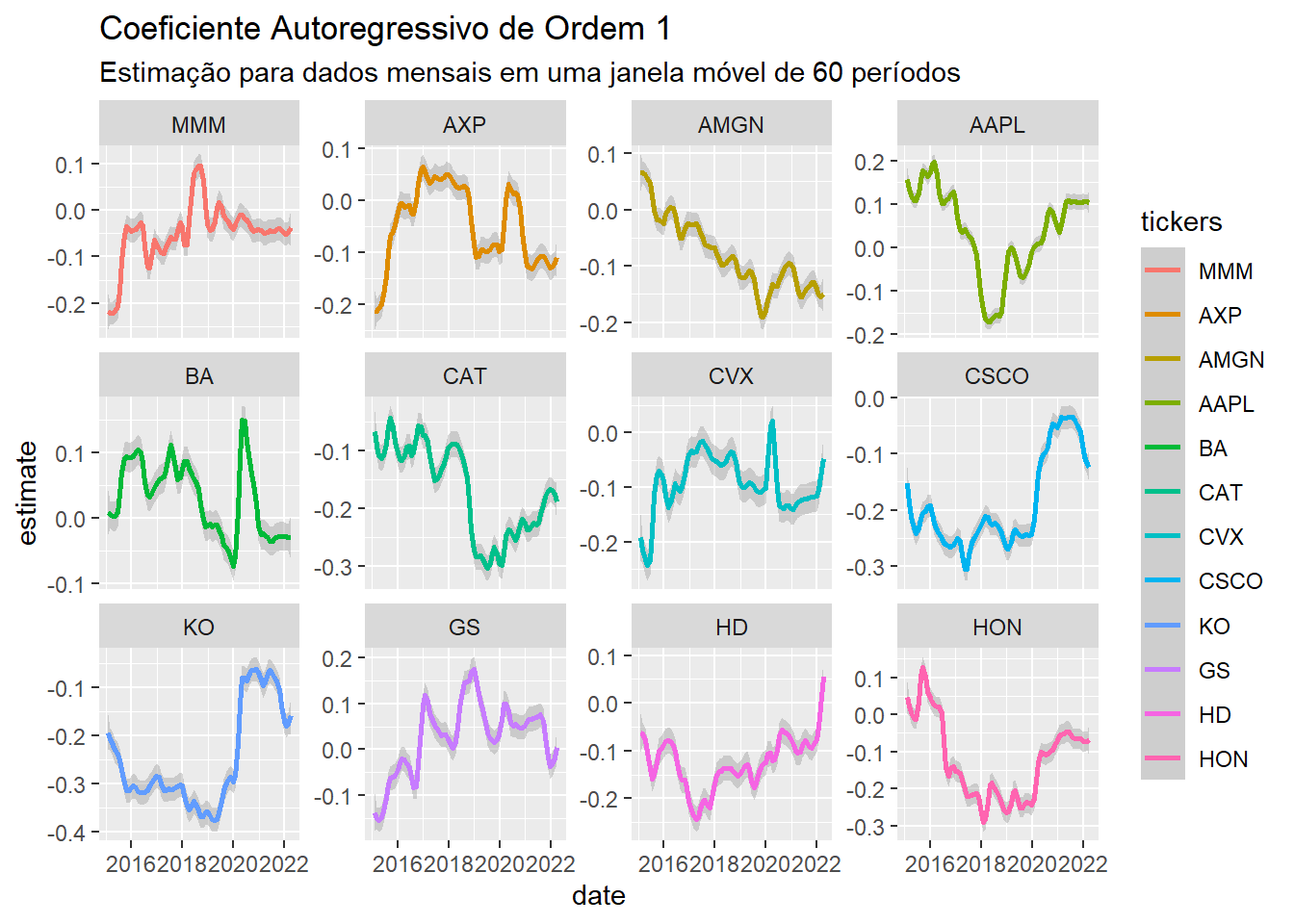
Seguindo esse workflow, as principais métricas in-sample do modelo escolhido ficam acessíveis imediatamente e, assim como no gráfico anterior, o ggplot2 cai como uma luva:
models |>
dplyr::filter(term == "ar1") |>
ggplot(aes(x = date, y = estimate, color = tickers)) +
geom_smooth(span = 0.10) +
facet_wrap(~tickers, scales = "free_y") +
labs(title = "Coeficiente Autoregressivo de Ordem 1",
subtitle = "Estimação para dados mensais em uma janela móvel de 60 períodos")
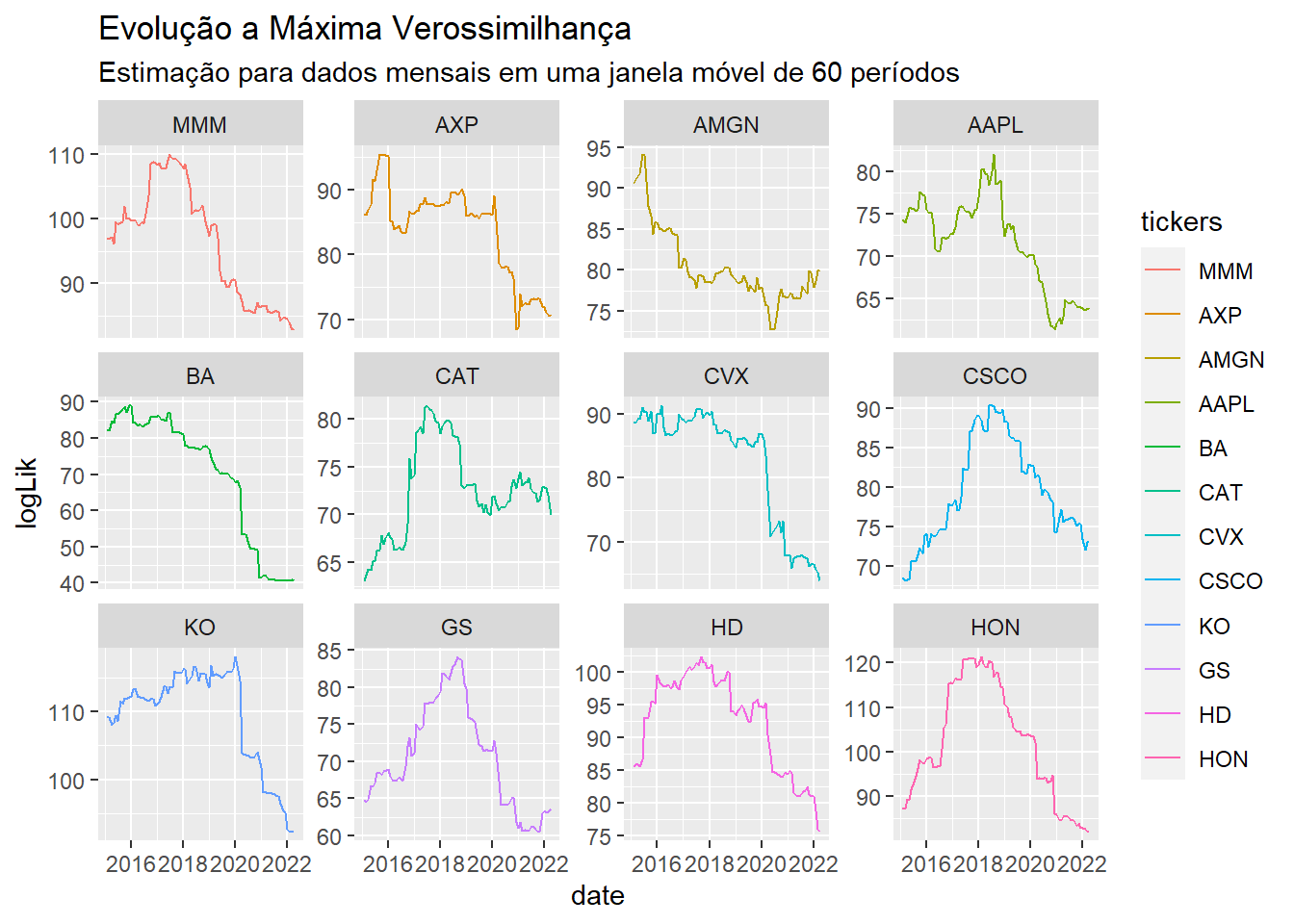
Para analisar o comportamento de outras métricas, o processo é semelhante. Por exemplo, o ponto de ótimo da máxima verossimilhança em cada instante do tempo pode ser visto com o comando:
models |>
ggplot(aes(x = date, y = logLik, color = tickers)) +
geom_line() +
facet_wrap(~tickers, scales = "free_y") +
labs(title = "Evolução a Máxima Verossimilhança",
subtitle = "Estimação para dados mensais em uma janela móvel de 60 períodos")
Em alguns casos, as métricas in sample não são tão relevantes. Nessas ocasiões, é necessário analisar a qualidade do modelo de outras maneiras. Se o objetivo da análise for previsão, Yahootickers oferece a dobradinha get_forecast() e get_metrics() para avaliação dos erros pseudo-fora da amostra:
metrics <- models |>
get_forecasts() |>
get_metrics(.group = tickers,
.truth = adjusted,
.forecast = point_forecast)
metrics
## # A tibble: 12 x 6
## tickers mse rmse mae mape mase
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 MMM 0.00312 0.0558 0.0424 119. 0.0663
## 2 AXP 0.00518 0.0720 0.0489 155. 0.198
## 3 AMGN 0.00478 0.0691 0.0534 132. 0.128
## 4 AAPL 0.00653 0.0808 0.0675 364. 0.229
## 5 BA 0.0117 0.108 0.0740 223. 0.110
## 6 CAT 0.00584 0.0764 0.0629 121. 0.127
## 7 CVX 0.00607 0.0779 0.0562 169. 0.101
## 8 CSCO 0.00489 0.0699 0.0541 209. 10.0
## 9 KO 0.00231 0.0481 0.0357 114. 0.283
## 10 GS 0.00668 0.0817 0.0630 109. 0.394
## 11 HD 0.00397 0.0630 0.0486 489. 0.134
## 12 HON 0.00314 0.0561 0.0402 591. 0.173
Perceba que, mais uma vez, a utilização do ggplot2 é imediata:
metrics |>
dplyr::mutate(tickers = forcats::fct_reorder(tickers, mse)) |>
ggplot(aes(x = tickers, y = mse, fill = tickers)) +
geom_col() +
labs(title = "Erro Quadrático Médio",
subtitle = "Estimação para dados mensais em uma janela móvel de 60 períodos")
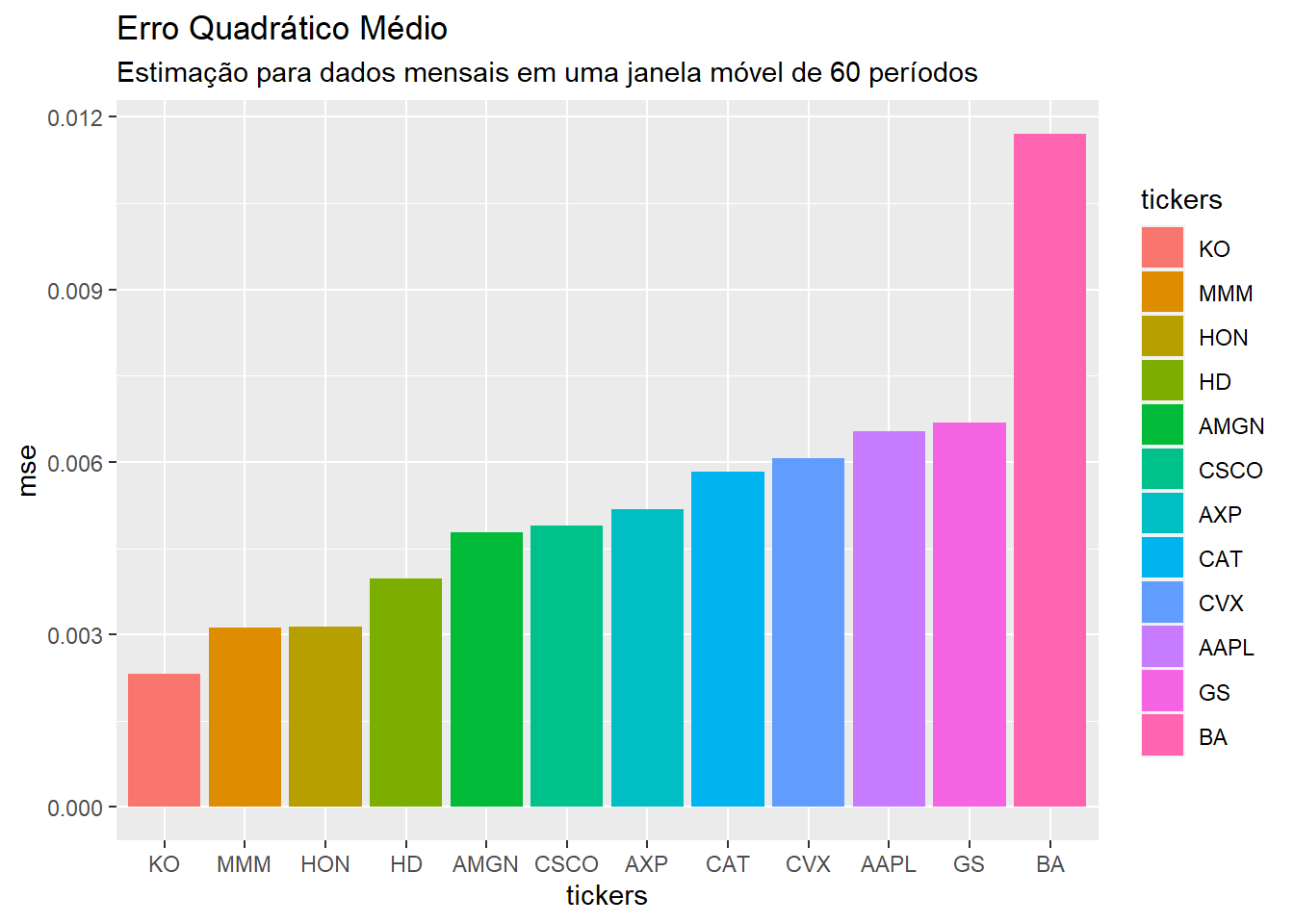
Enfim, o pacote possui uma estrutura bem delineada que funciona da seguinte forma:
### -- YahooTickers Workflow -- ###
# get_tickers() |>
# get_stocks() |>
# get_models() |>
# get_forecasts() |>
# get_metrics()
Obviamente, o API não foi desenvolvido para análises muito complexas, a principal função é coletar dados e fazer a coisa acontecer rapidamente, sem for loops e em um formato human readable.
Como mencionado anteriormente, o pacote atualmente suporta até 23 bolsas mundiais, mas como nem tudo é perfeito, a detecção de quais ações compôem quais índices é um processo complicado, que envolve web scrapping de sites públicos, em constante transformação. Com isso, o código as vezes quebra.
Sobre esse ponto, gostaria de mencionar que faço meu melhor para manter aquilo que já foi produzido sempre funcionando e foi assim que essa bibiliteca sobreviveu ao longo dos últimos 3 anos. Não há segredo: quanto mais pessoas utilizarem o API, maior o accountability e mais rápido futuros erros poderão ser corrigidos.
Por fim, se você chegou até aqui, talvez tenha interesse em olhar a documentação, onde é possível checar em maior nível de detalhe as funções utilizadas nesse post: https://reckziegel.github.io/YahooTickers/.
Por hoje é isso e happy-modeling!